


A novel way of improving the quality of students scientific research works
The reality, of a student, is much different from all those wise men in science and is lacking proper guidance and teaching on how to successfully publish a scientific paper article in a Journal ...

Lately, I’ve been reading ….my excuses, “online video reading”, about the publishing process a student needs to ….learn in order, not only to be able to format the paper presentation according to peer reviewers and evaluators but also the attention to the type of English language used throughout the document, as many, many Journals have strict language lexicon for publishing admission. Furthermore, is also found here and there on the internet, the shortcomings of the current publication methodologies in particular what concerns and defines value in a scientific article. Many solutions can be found, from the decades-old “impact factor“ to the more recent one known as “metrics“ (for sake of simplicity, I suppose ).
The reality, of a student, is, in fact, much different from all those wise men in science, and is lacking proper guidance and teaching on how to successfully publish a scientific paper article in a Journal of the student’s choice. And the main obstacle in science is the absence of #feedback, a well-thought-out comment about the work that is being submitted.
For almost a decade now, in the computer programmer world, exists an online platform that addresses this same issue. In the programmer’s case, the difficulties were on finding solutions for unknown programming code bugs that required extensive study and time to solve. The platform is known as StackOverFlow and is today, the place to go, when a coder has a doubt, a question, or even an issue about his/her coding work.
StackOverflow's success is not by chance, from start it was thought out and uses a new formula of evaluating user participation on the website. The following activities can be found:
ask a question
answer a question
comment a question
vote a question
downvote a question
post bounties to a question
…
I’m not going into detail about how the reputation is calculated on that particular platform, nor is the most relevant characteristic about the website. To me, as a programmer with more than 30 years of experience, the most important characteristic is how easy is to participate in collaboration without interrupting anyone’s schedule.
This same type of collaboration is what’s missing among scientific researchers. Many times fearing the loss of their authorship rights. Many times simply because is unknown in the research group.
Here’s my challenge for you, reading this text: Copy the framework structure of the website and make simple adjustments towards the needs of a student researcher in science. What can be done: from making questions about a general line of works at a laboratory to searching for answers for a particular mathematical formula or theoretical model. In reality, anything can be asked as long as it is about daily life in science, whether at a lab or in the open field. For instance, and some readers will find this, what I am about to say, next to impossible, the sharing of graphical data plots or even data tables with the same purpose, get answers for a #scienceBug!
All is needed it will do it since the online tool is already available to implement using open source software code. With some adjustments, as is typical when coding open-source code. Main objective: provide, mentoring and training to young researchers and assist them with the smallest contribution of all, a comment, but at the same time a very useful and many times a lifesaver for the researcher looking for an answer. Only good and improvement of quality of works can be found when one travels in this direction and way of doing works collaboratively (async.)
Bellow is one paper I found on google, for those who are motivated by the idea proposed above and want to read a bit more. Many more can be found on Google.

This article is looking for sponsors to grow. Consider giving a donation by Paypal to the author using the email mtpsilva@gmail.com or at least buy him a coffee by clicking on the above image link.
As part of my research on online live writing, no proofreading was made to this text. Only Basic automated corrections. Over time the reader can expect additional changes to the text without prior notification: bugs and error correction, but also for content adding. So make sure to check back later the article.
If the reader, instead, prefers reading well-formatted text paragraphs, error-free; perfect notations; high-resolution graphics, figures, photos, and videos, please consider subscribing on substack.com to a monthly or yearly plan. To do so, the reader can start by clicking on the “subscribe now” button above.
STUDY OF THE TEMPORAL-STATISTICS-BASED REPUTATION MODELS FOR Q&A SYSTEMS
Paulina Adamska, Marta Ju´zwin
one can download this paper here: https://core.ac.uk/download/pdf/236278561.pdf
Abstract
Q&A systems are becoming a vital source of knowledge in many different do-mains. In some cases, they are also associated with services that provide employers with important information regarding the expertise of their potential employees. Therefore, the reputation earned in such communities can be associated with better job opportunities, and its significance is increasing. However, in a community where there is no direct financial motivation for participation, a reputation score is not solely an expertise metric. It is also a powerful motivator for remaining an active community member. Regardless of this complexity, algorithms for calculating reputation scores need to be as easy to understand (and implement) as possible. Therefore, the designers of the Q&A reputation system often implement a set of fixed rules, to some extent trading quality for quantity. Our goal is to study whether (and how) temporal statistics of a Q&A website can be incorporated into its reputation system. We want the proposed mechanism to dynamically adjust the impact of a single-answer evaluation on the reputation of its producer. We would like the proposed model to accurately reflect the expertise of content producers.
Keywords: Q&A systems, reputation systems, expertise, online communities
1. Introduction
Reputation systems are well-known and widely-applied mechanisms used to enforce certain rules in online communities. They are particularly important and studied in the context of e-commerce [1, 5, 7, 10]; however, various implementations of such mechanisms are also introduced to different types of services, such as those devoted to content sharing (like reddit1) or those supporting sharing knowledge (like Q&A services). In such communities, the role of reputation systems is twofold. First of all they provide motivation for remaining an active provider of high-quality content. On the other hand, reputation also substitutes for an expertise metric in various types of ranks and is therefore strongly associated with the credibility of a community member. Researchers have already tried to speculate which properties of the produced content may be good expertise indicators [4] and tried to propose alter-native reputation algorithms. The accuracy of the proposed approaches (in terms of reflecting user expertise) was evaluated against some reference metrics and compared to solutions implemented in real communities. Nevertheless, in such solutions, a single modification of a thread associated with a certain question usually requires multiple reputation score recalculations. To the best of our knowledge, there is no extensive study of models utilizing temporal statistics to dynamically self-adjust the impact of a single-answer evaluation on the reputation of its producer in the context of Q&A platforms. In this work, we study whether replacing the set of fixed rules with such self-adjusting values can potentially make a reputation score a better expertise metric. The proposed models do not require any reputation gain recalculations when statistics change, so they are still computationally simple and easy to understand.
We compare the performance of the proposed approaches to the standard reputation system (implemented by Q&A websites from the Stack Exchange2 family) as well as the collaboration-based approach proposed by McNally et al. [6].
2. Related work
Researchers have already noticed that, in Q&A systems, the popularity of certain topics is the vital factor that influences the reputation of its contributors. This phenomenon refers both to the popularity of the general topic (for instance, a particular technology) and the popularity of the problem within the topic. The first aspect was mentioned by Bosu et al. [2], who discovered that expertise in some topics provides more opportunities to increase reputation by solving problems. However, unlike in our work, Bosu et al. measured popularity in terms of the number of questions. On the other hand, for each general topic, more- and less-common problems can be extracted. The first group yields more profits for contributors, but might not necessarily be correlated with the difficulty of a particular question, as complex issues often tend to be very specific or useful exclusively to experts. To mention some examples, there is a question on Stack Overflow (see Figure 1 that has received a high number of votes. This is obviously not posted to solve any important issue and does not require extensive knowledge nevertheless, it allows the respondent to significantly boost his reputation, even if the answer is not the first nor only one.
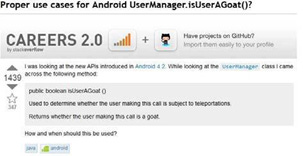
Figure 1. Stack Overflow – the first example of an extremely popular question.
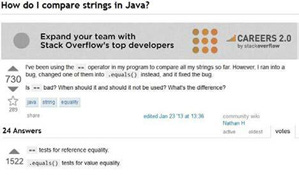
Figure 2. Stack Overflow – second example of an extremely popular question.
Apart from threads that have obviously been created for entertainment, there are also extremely popular posts that are associated with sharing very basic knowledge of a particular technology and can be answered with minimal effort, like the one regarding Java (presented in Figure 2).
The phenomenon of using upvotes to underscore the usefulness or entertainment value of posts makes it possible for community members to boost their reputations with minimal effort by actively posting easy yet very common questions, or by solving several common problems. The opportunity to utilize this mechanism is, to some extent, limited by the Community Wiki3 feature, which disables automatic reputation increments when certain content gets upvoted. However, in many cases, the decision of whether a particular post should be owned by the entire community is made directly by its members, so it depends both on user honesty and the individual interpretation of the term.
There have been many proposals of a different set of rules for computing the reputation of users and estimating the quality of posts on Stackoverflow. Romano and Pinzger [9] propose an algorithm for calculating answer scores, which aims to address the problem of the first answer having an advantage over those that follow, due to the fact that the computed score does not depend on evaluation time, and some of the voters might not have seen all of the answers at the moment of making their evaluations. The proposed algorithm assigns different weights to the votes, depending on the number of answers already posted when the evaluation was made. However, this approach still allows users to exploit popular threads, and it has only been studied in regards to whether this approach makes any difference in the system (namely, whether such an algorithm would choose different best answers). No analysis of how it is associated with the quality of the chosen content has been made.
McNally et al. [6] studied the impact of a collaboration-based reputation model on Stack Exchange websites. For each answer with a score greater than zero, its producer received a trust score proportional to the number of upvotes (in comparison to the sum of scores of all answers in the particular thread). This reputation algorithm has been evaluated by analyzing its correlation with the “ground-truth reputation score”, which was computed using the accepted answer rate for each answerer. This mechanism has also been proven to perform better than the original Stack Exchange approach (the original reputation score was normalized by the highest score in the system) as well as the Page Rank approach. The proposed solution helps to reduce the impact of more-popular questions and promotes the less-popular (and probably more costly to answer) ones, as they yield a better opportunity to maximize the potential gain of having even only one upvote. However, this method has one disadvantage, it requires the reputation of each question answerer to be recomputed every time a vote is submitted to any of the answers in the particular thread. This yields potential problems, both for the system designer (most of the existing web services choose to avoid such complexities and prefer to predefine a fixed set of possible reputation modification options, which can be manually tuned if it is necessary) and user experience (which is crucial for communities that rely on members volunteering to submit posts). For many users, it may be important to know that their reputation can only be decreased when his or her content gets downvoted and that it cannot be affected by changes of other answerer evaluations.
3. Experimental reputation systems
In this paper, we evaluate two experimental models. The first one (also referred to as temporal question score-based) adjusts the weight of each answer upvote using the temporal score of the associated question at the time of vote arrival. The reputation the increment for answerer u, after receiving an upvote for the answer to question q at time t, is computed according to the following formula:

where |score(q,t) | is the absolute value of the score of question qy (for which the answer is provided) at time t (which is the time of receiving an answer upvote). We use absolute value, assuming that a good answer can also be provided for a downvoted question. This model assumes that questions with a higher score are very often common issues that are easy to solve. Therefore, they do not necessarily indicate high expertise and should not be associated with an extremely high reputation gain.
The second model (also referred to as temporal answer number-based) is very similar; however, it utilizes a temporal answer number at the time of vote arrival. This approach should be more resilient to adversaries, as it takes more effort to manipulate the number of answers than to control the question score using the voting mechanism.
The reputation increment for answerer u, after receiving an upvote for the answer to question q at time t, is computed according to the following formula:

where |answers(q,t)| is the number of answers to question q (for which the evaluated answer is provided) at time t (which is the time of receiving an answer upvote). This model assumes that multiple answers for a single question may indicate that more users have some knowledge of the topic. Thus, such an issue may be easier to solve and should not be associated with an extremely high reputation score.
The proposed mechanisms do not introduce any punishment for submitting a down-voted answer. Both of them also assume that we do not update reputation gains when temporal statistics (used to compute them) change.
4. Analysis
In this section, we describe the dataset used in our analysis along with the research methodology. In the last subsection, we present the preliminary results.
4.1. Dataset
For the purpose of our analysis, we have extracted the publicly-available data regarding the activity of users over one year from StackOverflow, which is one of the most popular Q&A for programmers. The basic statistics regarding the dataset are presented in Table 1. Event history used to compute user reputation according to different algorithms consisted of post submissions (both questions and answers) and the chosen post evaluation activities (namely upvotes, downvotes, and answer acceptances).
4.2. Methodology
In order to provide some quality metric of the proposed approaches, we needed to choose some reference metric. We have chosen the collaboration-based approach. The main reason for our choice was that this approach does not promote popular topics. There are a fixed number of reputation points to win (namely, one point in the original proposal) for providing an answer to each question. The reputation gain of each answerer depends on the share of upvotes compared to the total number of upvotes in a particular thread. Such an environment makes it more profitable to answer more complex questions (as they may get fewer answers) and therefore maximize the chance of winning 100% of the points offered for answering a single question. Moreover, it does not depend on additional answer acceptances and allows better solutions to eventually be promoted regardless of the time of posting an answer.
We have used the previously-described event trace and computed the reference reputation score using the original collaboration-based algorithm. Both reference and experimental reputation scores were normalized using the maximum reputation generated by the studied mechanism to keep all of the computed values within the h0, 1i range. After that, reference values were sorted into descending value and matched with the corresponding values computed using the evaluated algorithms. Thus, we were able to compare the final score of each user for both the reference and experimental algorithms. Following McNally et. al. [6], we have computed Spearman correlations between the normalized reference reputation scores in our experiments, and the experimental ones for the best n users from the reference rank, were n ∈ 50, 100, 150, . . . , 500, all.
To additionally estimate the performance of the studied approaches, we have also computed a benchmark reputation score, which was the standard StackOverflow approach. In our calculations of the StackOverflow reputation scores, we have only considered answer upvotes (increasing reputation by 10 points), answer downvotes (decreasing reputation by 2 points), and answer acceptances (increasing reputation by 15 points). We did not implement any additional rules (like reputation decrease for downvoters, as there is no information about the voter in the publicly-available dataset).
4.3. Reference metric considerations
In order to provide some quality metric of the collaboration-based approach, we have used the previously-described event trace and computed reference reputation scores using two different algorithms. The first one is a simple mechanism based on the answer acceptance rate, as proposed by McNally et al. [6]; however, we made one important modification. This approach assigns a higher weight to answers to those questions that have received less attention from the community and therefore received fewer answers. Assuming Aqi being the entire set of answers to question I at the end of the observed time period, the reputation score, in this case, is increased by indeed solved the problem stated by the question asker, and it is independent of topic popularity, as there is only one point of reputation to gain for providing an answer to a single question. Moreover, it rewards solving problems that may be potentially more specialized, more difficult, or require additional effort (ex. some experiments). Such intuition is supported by Pal et al. [8], who has verified the hypothesis that experts tend to answer lower-value questions where higher value yields a higher total answer score in a particular thread and the presence of an accepted answer.
To some extent, the first reference metric incorporates question difficulty. For each accepted answer, its author receives a number of points proportional to the total number of answers to a particular question at the end of the observed time period. This intuition is supported by the assumption that the more users are able to provide any solution to the problem (regardless its quality) or believe to have some knowledge on the topic, the more common an issue is considered in this particular thread. On the other hand, Hanrahan et.al. [3] proposed using the duration between the time of posting a question and answer acceptance to estimate question difficulty. The quality of this difficulty metric has not been verified in any way by the authors of this proposal and may have two potential drawbacks. It is unclear to what extent the time needed to post an accepted answer estimates the actual difficulty of the solved issue, and to what extent it is the estimator of some personal traits of the question asker. We can imagine a community member who is extremely fastidious and always waits for the most-accurate answer, another person who accepts even a partial solution if it gives some good ideas quickly enough, or perhaps even a third person who rarely uses the accept option at all. Nevertheless, we have decided to take such a reference metric into consideration as well. In our analysis, we were not able to extract the exact acceptance time from the public data dump (only the date was provided). Instead, we chose to use the time needed to provide an answer that was eventually accepted. If there was no accepted answer to a particular question available in the dataset, we calculated the time between question posting and the date of the last post available in the database. Later on, the times were normalized and used to compute the potential new reference scores. For each answer acceptance, a community member could increase his reputation by the amount of points proportional to the time between posting the question and submitting the accepted answer.
To additionally estimate the performance of the collaboration-based approach, we have also computed a benchmark reputation score (which was the standard StackOverflow approach). Both reference and experimental reputation scores were preprocessed as described in section 4.2.
The results for the first reference metric show that the performance of the collaboration-based approach is significantly better than the Stack Overflow approach, not only for the simple acceptance-rate-based approach (as described in the original paper) but also for our weighted acceptance rate (see Figure 3). The results for the second reference metric are presented in Figure 4. Interestingly, we can observe that, for the group of best users, the correlations for both metrics are comparatively similar and extremely poor. Nevertheless, the collaboration-based reputation performance seems to be as good as the Stack Overflow approach.

Figure 3. Weighted acceptance rate used as the reference reputation.
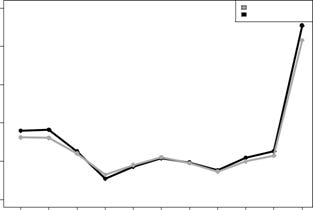
Figure 4. Acceptance time used as the reference reputation.
For evaluation purposes, we assume, that the behavior of honest content evaluators is not altered by the new rules, as the proposed reputation score only affects the reputations of question answerers. Adversary-resilience analysis is outside the scope of this paper.
4.4. Experimental approaches evaluation
In our experiments, we have compared the benchmark approach and our experimental reputation models to the collaboration-based reference score. The results for both experimental reputation systems are depicted in Figure 5. As we can see, the temporal question score-based approach is more successful in mimicking the collaboration-based rank than the original StackOverflow approach. We can observe even better results in the case of the second experimental mechanism (based on temporal answer number). This improvement can be associated with one of the features of the reference metric; namely, its indirect dependency on the answer number (the fewer different answers available, the better chance of getting the largest reputation gain due to a lack of competition). As previously mentioned, the temporal answer number-based model is also potentially better in terms of adversary resilience, as it is more costly to manipulate this statistic.

Figure 5. Performance of the proposed reputation models.
5. Conclusions and future work
According to our preliminary results, it seems to be possible to incorporate temporal statistics into Q&A reputation systems. We have shown that such an approach, although extremely simple, can also be surprisingly accurate with respect to our reference score. We are planning to further verify this hypothesis using data from different Q&A websites and investigate some more sophisticated reputation models involving temporal statistics, along with their resilience to adversaries. We would also like to verify the effectiveness of various reputation mechanisms in terms of user-expertise approximation, utilize different reference scores (and take into account manually-evaluated difficulty levels of a chosen set of questions), and check the computational complexity of the proposed models.
Acknowledgments
This work is supported by the Polish National Science Center grant 2012/05/B/ ST6/03364.
References
[1] Borzymek P., Sydow M., Wierzbicki A.: Enriching Trust Prediction Model in Social Network with User Rating Similarity. In: Ajith Abraham, Vaclav Snasel, eds, Proceedings of the 1st International Conference on Computational Aspects of Social Networks (CASoN 2009), pp. 40–47, IEEE Computer Society, Los Alamitos, NY, USA, 2009.
[2] Bosu A., Corley C. S., Heaton D., Chatterji D., Carver J. C., Kraft N. A.: Building
Reputation in StackOverflow: An Empirical Investigation. In: Proceedings of the 10th Working Conference on Mining Software Repositories, MSR ’13, pp. 89–92. IEEE Press, Piscataway, NJ, USA, 2013, http://dl.acm.org/citation.cfm? id=2487085.2487107.
[3] Hanrahan B. V., Convertino G., Nelson L.: Modeling problem difficulty and expertise in StackOverflow. In: CSCW ’12 Computer Supported Cooperative Work, Seattle, WA, USA, February 11–15, 2012 – Companion Volume, pp. 91–94, 2012, http://dx.doi.org/10.1145/2141512.2141550.
[4] Kao W., Liu D., Wang S.: Expert finding in question-answering websites: a novel
hybrid approach. In: Proceedings of the 2010 ACM Symposium on Applied Computing (SAC), Sierre, Switzerland, March 22-26, 2010, pp. 867–871, 2010, http://dx.doi.org/10.1145/1774088.1774266.
[5] Kaszuba T., Hupa A., Wierzbicki A.: Advanced Feedback Management for Internet Auction Reputation Systems. IEEE Internet Computing, vol. 14(5), pp. 31–37, 2010, http://dx.doi.org/10.1109/MIC.2010.85.
[6] McNally K., O’Mahony M. P., Smyth B.: A Model of Collaboration-based Repu-
tation for the Social Web. In: Proceedings of the Seventh International Conference on Weblogs and Social Media, ICWSM 2013, Cambridge, Massachusetts, USA, July 8–11, 2013, 2013, http://www.aaai.org/ocs/index.php/ICWSM/ICWSM13/ paper/view/6112.
[7] Morzy M., Wierzbicki A.: The Sound of Silence: Mining Implicit Feedbacks to
Compute Reputation. In: Internet and Network Economics, Second International Workshop, WINE 2006, Patras, Greece, December 15–17, 2006, Proceed-ings, pp. 365–376, 2006, http://dx.doi.org/10.1007/11944874_33.
[8] Pal A., Harper F. M., Konstan J. A.: Exploring Question Selection Bias to Identify Experts and Potential Experts in Community Question Answering. ACM Transaction Information Systems, vol. 30(2), p. 10, 2012, http://dx.doi.org/ 10.1145/2180868.2180872.
[9] Romano D., Pinzger M.: Towards a Weighted Voting System for Q&A Sites. In: 2013 IEEE International Conference on Software Maintenance, Eindhoven, The Netherlands, September 22–28, 2013, pp. 368–371, 2013, http://dx.doi.org/ 10.1109/ICSM.2013.49.
[10] Wierzbicki A.: The Case for Fairness of Trust Management. Electron. Notes Theor. Comput. Sci., vol. 197(2), pp. 73–89, 2008, http://dx.doi.org/10. 1016/j.entcs.2007.12.018.
Affiliations
Paulina Adamska
Polish-Japanese Academy of Information Technology, Warsaw, Poland, tiia@pjwstk.edu.pl
Marta Ju´zwin
Polish-Japanese Academy of Information Technology, Warsaw, Poland, marta.juzwin@pjwstk.edu.pl